Codificación amplia supera el ruido
Nuestra investigación sobre un juego de palabras muestra que las restricciones imponen un límite a la variación. No puede haber una variación ilimitada cuando hay una restricción estricta en el rango de un paso de cambio. Los lenguajes naturales aprovechan los límites de variación para proteger sus mensajes de la interferencia del ruido. Los organismos vivos tienen las características de diferentes especies codificadas en su ADN, un sistema similar al lenguaje. El lenguaje del ADN protege el proceso de reproducción natural de muchos errores simples que podrían producir defectos de nacimiento.
El tipo de ruido más probable corresponde a pequeños pasos, esos que podrían cambiar una sola letra en un mensaje. Los lenguajes naturales protegen los mensajes contra la corrupción del ruido intercalando cadenas de letras que no son palabras entre las palabras aceptadas del lenguaje. El lenguaje natural del ADN previene los errores de reproducción al intercalar secuencias de ADN que no codifican ninguna proteína construible entre segmentos de código de ADN que sí proporcionan instrucciones para ensamblar proteínas. Con espacios amplios, una pequeña cantidad de ruido cambia una palabra o un segmento de código en una secuencia sin sentido fácilmente reconocible. Es poco probable que el ruido dé el gran salto a otra palabra o segmento de código aceptable que no formaba parte del mensaje original.
Debemos introducir los conceptos de conjuntos, matrices y espacios para ver cómo funciona esto. Un conjunto contiene un montón de elementos. Los artículos no necesitan estar en ningún orden. Pueden ser un revoltijo desorganizado. Podemos caracterizar un conjunto por su tamaño, el número de elementos. El conjunto de todas las cadenas de dos letras posibles tiene 729 elementos. El subconjunto de todas las palabras en español de dos letras tiene 59 elementos.
Podemos imponer algún orden en el revoltijo ordenando alfabéticamente las cadenas. El orden es arbitrario porque la secuencia de letras en el alfabeto es convencional. Ordenar alfabéticamente por cada letra a su vez comenzando con la primera letra convierte un conjunto de cadenas en una lista. Hay otra forma de alfabetizar. Podemos organizar cadenas de dos letras en una tabla si ordenamos alfabéticamente la primera letra en filas y la segunda letra en columnas.
Continuando con esta idea, podemos introducir el concepto de matriz. Una lista es una matriz de cadenas de una letra. Una tabla es una matriz de cadenas de dos letras y la tabla es cuadrada. Una matriz de cadenas de tres letras apila 27 tablas cuadradas en orden alfabético por la tercera letra, formando un cubo. Podemos ubicar una palabra de tres letras en tal matriz por su fila, columna y letra de la tabla. Podemos visualizar una matriz de cadenas de tres letras con un modelo tridimensional. Suponga que las 27 tablas cuadradas de cadenas de tres letras están impresas en 27 páginas secuenciales de un libro, con las páginas ordenadas por la tercera letra de la cadena. El libro no será cúbico porque el papel es mucho más delgado que el largo o el ancho de cualquiera de las tablas, pero podemos pensar que la matriz es cúbica.
Si vamos a cadenas de cuatro letras, necesitamos poner 27 matrices cúbicas en orden alfabético por la cuarta letra. Esto técnicamente hace que la matriz sea un cubo de cuatro dimensiones, pero pocas personas pueden visualizar tal objeto. En general, podemos organizar cadenas de cualquier longitud dada n en una matriz multidimensional que es un cubo de n dimensiones. ¿Suena complejo? Organizar palabras en arreglos multidimensionales es una forma de medir su complejidad.
Una matriz se convierte en un espacio si hay alguna forma de medir la distancia desde cualquier elemento de la matriz a cualquier otro elemento de la matriz. En el espacio geométrico usamos el Teorema de Pitágoras para medir la distancia. El cuadrado de la distancia diagonal es la suma de los cuadrados de las distancias a lo largo de cada fila, columna o borde de la matriz. Hay formas más sencillas de medir la distancia. Podemos definir la distancia entre dos palabras como el número mínimo de movimientos hacia arriba o hacia abajo, hacia la izquierda o hacia la derecha, de mesa en mesa, para pasar de una palabra a otra. Esto podría llamarse la distancia de "manzana de la ciudad", porque en una ciudad uno debe dar la vuelta a las esquinas en lugar de atravesar lotes baldíos.
De la teoría de la información aprendemos que todos los lenguajes naturales tienen amplios espacios de codificación entre las palabras aceptadas para proteger los mensajes contra el ruido. Los espacios pueden entenderse con la ayuda de una tabla. Colocamos las 59 palabras en español de dos letras en un espacio de codificación con todas las palabras que comienzan con a en la primera fila, todas las palabras que comienzan con b en la segunda fila, etc. Luego colocamos todas las palabras en una fila alfabéticamente y las espaciamos en columnas según su segunda letra. Esto da la tabla que se muestra a continuación.
Nuestra investigación sobre un juego de palabras muestra que las restricciones imponen un límite a la variación. No puede haber una variación ilimitada cuando hay una restricción estricta en el rango de un paso de cambio. Los lenguajes naturales aprovechan los límites de variación para proteger sus mensajes de la interferencia del ruido. Los organismos vivos tienen las características de diferentes especies codificadas en su ADN, un sistema similar al lenguaje. El lenguaje del ADN protege el proceso de reproducción natural de muchos errores simples que podrían producir defectos de nacimiento.
El tipo de ruido más probable corresponde a pequeños pasos, esos que podrían cambiar una sola letra en un mensaje. Los lenguajes naturales protegen los mensajes contra la corrupción del ruido intercalando cadenas de letras que no son palabras entre las palabras aceptadas del lenguaje. El lenguaje natural del ADN previene los errores de reproducción al intercalar secuencias de ADN que no codifican ninguna proteína construible entre segmentos de código de ADN que sí proporcionan instrucciones para ensamblar proteínas. Con espacios amplios, una pequeña cantidad de ruido cambia una palabra o un segmento de código en una secuencia sin sentido fácilmente reconocible. Es poco probable que el ruido dé el gran salto a otra palabra o segmento de código aceptable que no formaba parte del mensaje original.
Debemos introducir los conceptos de conjuntos, matrices y espacios para ver cómo funciona esto. Un conjunto contiene un montón de elementos. Los artículos no necesitan estar en ningún orden. Pueden ser un revoltijo desorganizado. Podemos caracterizar un conjunto por su tamaño, el número de elementos. El conjunto de todas las cadenas de dos letras posibles tiene 729 elementos. El subconjunto de todas las palabras en español de dos letras tiene 59 elementos.
Podemos imponer algún orden en el revoltijo ordenando alfabéticamente las cadenas. El orden es arbitrario porque la secuencia de letras en el alfabeto es convencional. Ordenar alfabéticamente por cada letra a su vez comenzando con la primera letra convierte un conjunto de cadenas en una lista. Hay otra forma de alfabetizar. Podemos organizar cadenas de dos letras en una tabla si ordenamos alfabéticamente la primera letra en filas y la segunda letra en columnas.
Continuando con esta idea, podemos introducir el concepto de matriz. Una lista es una matriz de cadenas de una letra. Una tabla es una matriz de cadenas de dos letras y la tabla es cuadrada. Una matriz de cadenas de tres letras apila 27 tablas cuadradas en orden alfabético por la tercera letra, formando un cubo. Podemos ubicar una palabra de tres letras en tal matriz por su fila, columna y letra de la tabla. Podemos visualizar una matriz de cadenas de tres letras con un modelo tridimensional. Suponga que las 27 tablas cuadradas de cadenas de tres letras están impresas en 27 páginas secuenciales de un libro, con las páginas ordenadas por la tercera letra de la cadena. El libro no será cúbico porque el papel es mucho más delgado que el largo o el ancho de cualquiera de las tablas, pero podemos pensar que la matriz es cúbica.
Si vamos a cadenas de cuatro letras, necesitamos poner 27 matrices cúbicas en orden alfabético por la cuarta letra. Esto técnicamente hace que la matriz sea un cubo de cuatro dimensiones, pero pocas personas pueden visualizar tal objeto. En general, podemos organizar cadenas de cualquier longitud dada n en una matriz multidimensional que es un cubo de n dimensiones. ¿Suena complejo? Organizar palabras en arreglos multidimensionales es una forma de medir su complejidad.
Una matriz se convierte en un espacio si hay alguna forma de medir la distancia desde cualquier elemento de la matriz a cualquier otro elemento de la matriz. En el espacio geométrico usamos el Teorema de Pitágoras para medir la distancia. El cuadrado de la distancia diagonal es la suma de los cuadrados de las distancias a lo largo de cada fila, columna o borde de la matriz. Hay formas más sencillas de medir la distancia. Podemos definir la distancia entre dos palabras como el número mínimo de movimientos hacia arriba o hacia abajo, hacia la izquierda o hacia la derecha, de mesa en mesa, para pasar de una palabra a otra. Esto podría llamarse la distancia de "manzana de la ciudad", porque en una ciudad uno debe dar la vuelta a las esquinas en lugar de atravesar lotes baldíos.
De la teoría de la información aprendemos que todos los lenguajes naturales tienen amplios espacios de codificación entre las palabras aceptadas para proteger los mensajes contra el ruido. Los espacios pueden entenderse con la ayuda de una tabla. Colocamos las 59 palabras en español de dos letras en un espacio de codificación con todas las palabras que comienzan con a en la primera fila, todas las palabras que comienzan con b en la segunda fila, etc. Luego colocamos todas las palabras en una fila alfabéticamente y las espaciamos en columnas según su segunda letra. Esto da la tabla que se muestra a continuación.
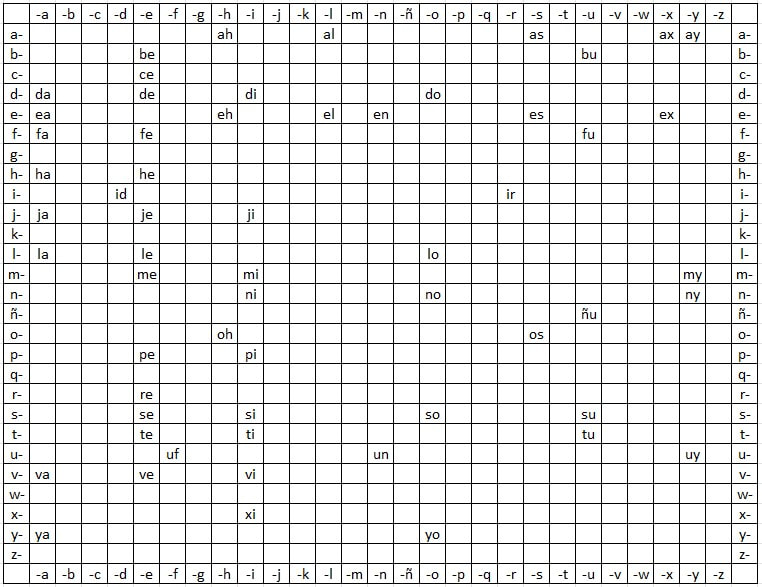
Notamos que la mayoría de las palabras están separadas de las demás por más de una columna en una fila, o por más de una fila en una columna. Las únicas palabras adyacentes en las filas son "el" y "en." Las únicas palabras adyacentes en las columnas son "da," "ea," y "fa;" "be," "ce," y "de;” “le” y “me;” "re," "se," y "te;" "mi" y "ni;” “si” y “ti;” y "su" y "tu;” y “my” y “ny.” En la siguiente tabla, hemos reemplazado cada palabra con su distancia de filas y columnas a su vecino más cercano.

La suma de los 59 números incluidos arriba es 127. El espacio promedio entre los vecinos más cercanos es 127/59 = 2,15 movimientos. La ocupación, o número de palabras dividido por el número de espacios, es 59/729 = 8,09%.
Para poner la escasa ocupación del hiperespacio del alfabeto de otra manera, supongamos que una palabra "promedio" de dos letras ocupa una sola celda en el espacio bidimensional que se muestra arriba, pero está rodeada por una capa de celdas vacías de una celda de espesor. Entonces, cada una de las 59 palabras necesitaría 9 celdas. Habría 9 x 59 = 531 celdas ocupadas de un total de 27 x 27 = 729 celdas. Es decir, con una capa mínima de una celda de espesor alrededor de cada palabra, solo se llena 531/729 = 72,8% del espacio.
El espacio de las palabras de tres letras es 27 x 27 x 27 = 19.683 celdas. Incruste cada una de las 143 palabras aceptadas españolas en un cubo con paredes de una celda de espesor. El cubo estaría formado por 3 x 3 x 3 = 27 celdas. Por lo tanto, con cada palabra rodeada por una capa de una celda de espesor, solo se ocupan 143 x 27 = 9180 celdas. El porcentaje de llenado desciende a 9.180/19.683 = 46,6%.
El espacio de las palabras de cuatro letras es 27 x 27 x 27 x 27 = 531.441 celdas. Deje que cada una de las 297 palabras españolas aceptadas se incruste en un hipercubo con paredes de una celda de espesor. El hipercubo sería de 3 x 3 x 3 x 3 = 81 celdas. Así, con cada palabra rodeada por una capa de una celda de espesor, solo se ocupan 297 x 81 = 24.057 celdas. El porcentaje de relleno baja a 24.057/531.441 = 4,53%. Esto nos permite aumentar el hiperespacio alrededor de cada palabra a un hipercubo de cuatro dimensiones. El hipercubo que rodea una palabra tiene ahora 4 x 4 x 4 x 4 = 256 celdas. Las 297 palabras ocupan 297 x 256 = 76.032 celdas, que son 76.032/531.441 o el 14,3% del espacio disponible.
El espacio medio entre palabras es grande y la ocupación es muy inferior al 100 %. Hay una buena razón para esto. El español, como todos los idiomas naturales, utiliza la redundancia para ayudar a los oyentes a comprender, aunque haya ruido y haya errores de imprenta. A medida que el ambiente se vuelve más ruidoso, restringimos la cantidad de palabras que usamos y decimos cada una con más énfasis. Esto aumenta el espacio medio entre palabras. La tripulación de un bombardero que se comunica entre sí a través de un sistema de intercomunicación puede sustituir la palabra "negativo" por "no", porque "no" se confunde demasiado fácilmente con "adelante" en un entorno ruidoso.
El lenguaje escrito también es propenso a errores de transmisión. La escritura a mano no siempre es lo suficientemente clara para distinguir entre letras. Los errores tipográficos son fáciles de cometer. Veamos cómo el espaciado promedio entre las palabras anteriores y la escasa ocupación evita malentendidos derivados de errores de transmisión. Hay 22 filas que contienen palabras. En la fila que contiene las 6 entradas “ea eh el en es ex”, un solo error en la segunda letra de cualquier entrada tiene (6-1)/ (27-1) = 5/26 = 19 % de probabilidad de sustituir falsamente una palabra por otra palabra. En las filas que contienen "ce ñu re xi", un solo error en la segunda letra de cualquier entrada tiene cero posibilidades de sustituir falsamente una palabra por otra palabra. La probabilidad promedio de un solo error en la segunda letra al sustituir falsamente una palabra por otra palabra es 1,09%. Un cálculo similar muestra que un solo error en la primera letra de una palabra tiene un 0,45 % de probabilidad de sustituir falsamente una palabra por otra palabra. Por lo tanto, un solo error en la primera o en la segunda letra tiene un 1,09 % + 0,45 % = 1,54 % de probabilidad de sustituir falsamente una palabra por otra palabra. Esto es ligeramente mejor que una oportunidad en sesentaicinco.
Supongamos que estamos enviando una palabra de dos letras como parte de un mensaje. El canal de comunicaciones puede tener ruido. El ruido toma muchas formas, dependiendo del tipo de canal de transmisión. El ruido incluye ampliamente errores tipográficos o de transcripción. Esperamos que los destinatarios al menos sepan si hubo un error en la transmisión para que puedan solicitar una retransmisión.
Del análisis anterior sabemos que, si el ruido corrompe la transmisión, hay un 1,45 % de posibilidades de que aparezca una palabra en español de dos letras en lugar de otra en el mensaje. Es posible que los destinatarios no noten el error. El mensaje corrupto podría engañarlos. Pero la mayoría de las veces, un solo error en una de las letras producirá una cadena de dos letras que nuestros destinatarios sabrán que no es una palabra en español. Esto muestra cómo el amplio espacio evita que el ruido corrompa el mensaje.
A medida que las palabras se hacen más largas, el espacio se vuelve más y más amplio. Por eso es más fácil detectar un error tipográfico cuanto más largas sean las palabras.
Los lectores humanos pueden procesar mensajes a nivel conceptual. Esto les permite detectar e incluso corregir muchos errores. Los programas informáticos todavía están muy atrasados. Los correctores gramaticales a menudo marcan errores en oraciones que son correctas pero que pueden tener estructuras inusuales. Por esta razón, los mensajes que controlan directamente a las computadoras, como el código del programa, generalmente deben estar libres de errores. Hay varios esquemas de detección y corrección de errores en uso.
Hay una buena razón para el amplio espacio en los lenguajes naturales. Sin embargo, es absurdo suponer que todos los creadores de una lengua pensaron en esa razón. Las personas acuerdan colectivamente las palabras y los significados de un idioma utilizando las facilidades racionales de sus mentes, pero muy pocas personas entienden lo que acabamos de explicar sobre el espaciado amplio. ¿Construimos colectiva e inconscientemente salvaguardias en nuestro idioma? El lenguaje muestra mucha evidencia de diseño, pero no podemos identificar a ningún diseñador humano. Quizás la gente aprendió colectivamente a hacer fácilmente distinguibles los sonidos de su sistema auditivo de signos.
En el siglo XX, los darwinistas intentaron explicar que los lenguajes evolucionaron por algún análogo del proceso de selección natural de Darwin, pero esa idea ahora está completamente desacreditada. Los lenguajes naturales primitivos son más complejos que los lenguajes modernos. El latín y el griego antiguo tenían declinaciones de casos, así como varias conjugaciones de verbos. Tenemos que aprender las terminaciones adecuadas para aplicarlas a diferentes sustantivos y verbos para escribir y hablar lenguas antiguas correctamente. Tales características continúan en mayor o menor grado en las lenguas modernas. El español tiene también plurales y conjugaciones. Básicamente, los idiomas se vuelven más simples cuando sus hablantes aprenden a escribirlos y cuando más y más personas los usan. Esto es justo lo contrario de la idea darwinista de construir desde lo simple hasta lo complejo.
Para poner la escasa ocupación del hiperespacio del alfabeto de otra manera, supongamos que una palabra "promedio" de dos letras ocupa una sola celda en el espacio bidimensional que se muestra arriba, pero está rodeada por una capa de celdas vacías de una celda de espesor. Entonces, cada una de las 59 palabras necesitaría 9 celdas. Habría 9 x 59 = 531 celdas ocupadas de un total de 27 x 27 = 729 celdas. Es decir, con una capa mínima de una celda de espesor alrededor de cada palabra, solo se llena 531/729 = 72,8% del espacio.
El espacio de las palabras de tres letras es 27 x 27 x 27 = 19.683 celdas. Incruste cada una de las 143 palabras aceptadas españolas en un cubo con paredes de una celda de espesor. El cubo estaría formado por 3 x 3 x 3 = 27 celdas. Por lo tanto, con cada palabra rodeada por una capa de una celda de espesor, solo se ocupan 143 x 27 = 9180 celdas. El porcentaje de llenado desciende a 9.180/19.683 = 46,6%.
El espacio de las palabras de cuatro letras es 27 x 27 x 27 x 27 = 531.441 celdas. Deje que cada una de las 297 palabras españolas aceptadas se incruste en un hipercubo con paredes de una celda de espesor. El hipercubo sería de 3 x 3 x 3 x 3 = 81 celdas. Así, con cada palabra rodeada por una capa de una celda de espesor, solo se ocupan 297 x 81 = 24.057 celdas. El porcentaje de relleno baja a 24.057/531.441 = 4,53%. Esto nos permite aumentar el hiperespacio alrededor de cada palabra a un hipercubo de cuatro dimensiones. El hipercubo que rodea una palabra tiene ahora 4 x 4 x 4 x 4 = 256 celdas. Las 297 palabras ocupan 297 x 256 = 76.032 celdas, que son 76.032/531.441 o el 14,3% del espacio disponible.
El espacio medio entre palabras es grande y la ocupación es muy inferior al 100 %. Hay una buena razón para esto. El español, como todos los idiomas naturales, utiliza la redundancia para ayudar a los oyentes a comprender, aunque haya ruido y haya errores de imprenta. A medida que el ambiente se vuelve más ruidoso, restringimos la cantidad de palabras que usamos y decimos cada una con más énfasis. Esto aumenta el espacio medio entre palabras. La tripulación de un bombardero que se comunica entre sí a través de un sistema de intercomunicación puede sustituir la palabra "negativo" por "no", porque "no" se confunde demasiado fácilmente con "adelante" en un entorno ruidoso.
El lenguaje escrito también es propenso a errores de transmisión. La escritura a mano no siempre es lo suficientemente clara para distinguir entre letras. Los errores tipográficos son fáciles de cometer. Veamos cómo el espaciado promedio entre las palabras anteriores y la escasa ocupación evita malentendidos derivados de errores de transmisión. Hay 22 filas que contienen palabras. En la fila que contiene las 6 entradas “ea eh el en es ex”, un solo error en la segunda letra de cualquier entrada tiene (6-1)/ (27-1) = 5/26 = 19 % de probabilidad de sustituir falsamente una palabra por otra palabra. En las filas que contienen "ce ñu re xi", un solo error en la segunda letra de cualquier entrada tiene cero posibilidades de sustituir falsamente una palabra por otra palabra. La probabilidad promedio de un solo error en la segunda letra al sustituir falsamente una palabra por otra palabra es 1,09%. Un cálculo similar muestra que un solo error en la primera letra de una palabra tiene un 0,45 % de probabilidad de sustituir falsamente una palabra por otra palabra. Por lo tanto, un solo error en la primera o en la segunda letra tiene un 1,09 % + 0,45 % = 1,54 % de probabilidad de sustituir falsamente una palabra por otra palabra. Esto es ligeramente mejor que una oportunidad en sesentaicinco.
Supongamos que estamos enviando una palabra de dos letras como parte de un mensaje. El canal de comunicaciones puede tener ruido. El ruido toma muchas formas, dependiendo del tipo de canal de transmisión. El ruido incluye ampliamente errores tipográficos o de transcripción. Esperamos que los destinatarios al menos sepan si hubo un error en la transmisión para que puedan solicitar una retransmisión.
Del análisis anterior sabemos que, si el ruido corrompe la transmisión, hay un 1,45 % de posibilidades de que aparezca una palabra en español de dos letras en lugar de otra en el mensaje. Es posible que los destinatarios no noten el error. El mensaje corrupto podría engañarlos. Pero la mayoría de las veces, un solo error en una de las letras producirá una cadena de dos letras que nuestros destinatarios sabrán que no es una palabra en español. Esto muestra cómo el amplio espacio evita que el ruido corrompa el mensaje.
A medida que las palabras se hacen más largas, el espacio se vuelve más y más amplio. Por eso es más fácil detectar un error tipográfico cuanto más largas sean las palabras.
Los lectores humanos pueden procesar mensajes a nivel conceptual. Esto les permite detectar e incluso corregir muchos errores. Los programas informáticos todavía están muy atrasados. Los correctores gramaticales a menudo marcan errores en oraciones que son correctas pero que pueden tener estructuras inusuales. Por esta razón, los mensajes que controlan directamente a las computadoras, como el código del programa, generalmente deben estar libres de errores. Hay varios esquemas de detección y corrección de errores en uso.
Hay una buena razón para el amplio espacio en los lenguajes naturales. Sin embargo, es absurdo suponer que todos los creadores de una lengua pensaron en esa razón. Las personas acuerdan colectivamente las palabras y los significados de un idioma utilizando las facilidades racionales de sus mentes, pero muy pocas personas entienden lo que acabamos de explicar sobre el espaciado amplio. ¿Construimos colectiva e inconscientemente salvaguardias en nuestro idioma? El lenguaje muestra mucha evidencia de diseño, pero no podemos identificar a ningún diseñador humano. Quizás la gente aprendió colectivamente a hacer fácilmente distinguibles los sonidos de su sistema auditivo de signos.
En el siglo XX, los darwinistas intentaron explicar que los lenguajes evolucionaron por algún análogo del proceso de selección natural de Darwin, pero esa idea ahora está completamente desacreditada. Los lenguajes naturales primitivos son más complejos que los lenguajes modernos. El latín y el griego antiguo tenían declinaciones de casos, así como varias conjugaciones de verbos. Tenemos que aprender las terminaciones adecuadas para aplicarlas a diferentes sustantivos y verbos para escribir y hablar lenguas antiguas correctamente. Tales características continúan en mayor o menor grado en las lenguas modernas. El español tiene también plurales y conjugaciones. Básicamente, los idiomas se vuelven más simples cuando sus hablantes aprenden a escribirlos y cuando más y más personas los usan. Esto es justo lo contrario de la idea darwinista de construir desde lo simple hasta lo complejo.